这几年Intel和AMD都推出了集成GPU的消费级CPU,并强调它们的内存是共享的架构,也就是UMA(Unified Memory Architeture)。最近AMD和NVIDIA的独立显卡也加入战团,开始逐步支持UMA。最新的D3D12直接内置了UMA的支持,开发者可以让自己的程序充分利用上UMA所带来的优势。那么UMA能带来什么好处?它的限制在哪里?
各种平台的状况
自从PC上第一块GPU,NVIDIA Geforce 256问世以来,GPU一直都是自带一块显存的。当年的AGP总线是非对称的设计,数据传到GPU要远快于从GPU读回。CPU和GPU的访存是完全分开的。后来的PCIE总线让两端传输的速度相等了,并提供了一些相互访问的能力。在驱动里,system memory的区域可以映射成可以被GPU访问的,反过来也可以。但之前的WDDM并没有直接提供这样的支持,只是把它当作一种“优化”,在必要的时候方便拷贝数据。有的硬件和驱动做不到互相访问,强制要求这个能力会影响兼容性。WDDM 2.0开始要求两端可以直接互访,这才解决了这个问题。
对游戏机来说,它们不需要考虑兼容问题,所以大多设计成UMA的架构。游戏也都会对此作很多优化,以节省内存并提升性能。拿XBox360为例,开发者可以做这样的事情:
char* p = new char[N];
vb->SetPointer(p);
这样就把一块new出来的内存设置给了vertex buffer作为其内部空间。这个vb可以接下去被GPU用于渲染。
至于移动平台,它们的CPU和GPU是一体的,内存访问也是通过同样的内存控制器。但因为驱动的限制,很多时候仍然会预留出一块内存,专门用于GPU。也就相当于是个显存了。直到最近移动驱动的发展,逐渐减少和取消了预留内存的做法,最多就是在系统启动的时候预留一下,之后就通用了。
所以可以看出,UMA已经存在了很长时间。但直到近期才开始被广泛接受,开始在PC和移动平台采用。
UMA能做什么
对于支持UMA的平台,开发者不需要把内存数据拷贝到显存。一方面,这样节省了空间,数据只要保持一份。对于移动平台来说,空间非常宝贵,省一倍相当可观了。另一方面,这提升了性能,因为不需要拷贝。长期以来在任何平台上,开发者都会尽量减少这样的拷贝,以至于每一帧需要拷贝的数据非常非常少,基本上只有粒子系统和UI。所以这带来的好处在移动平台和低端PC上还有一点,高端PC就几乎没有性能区别了。
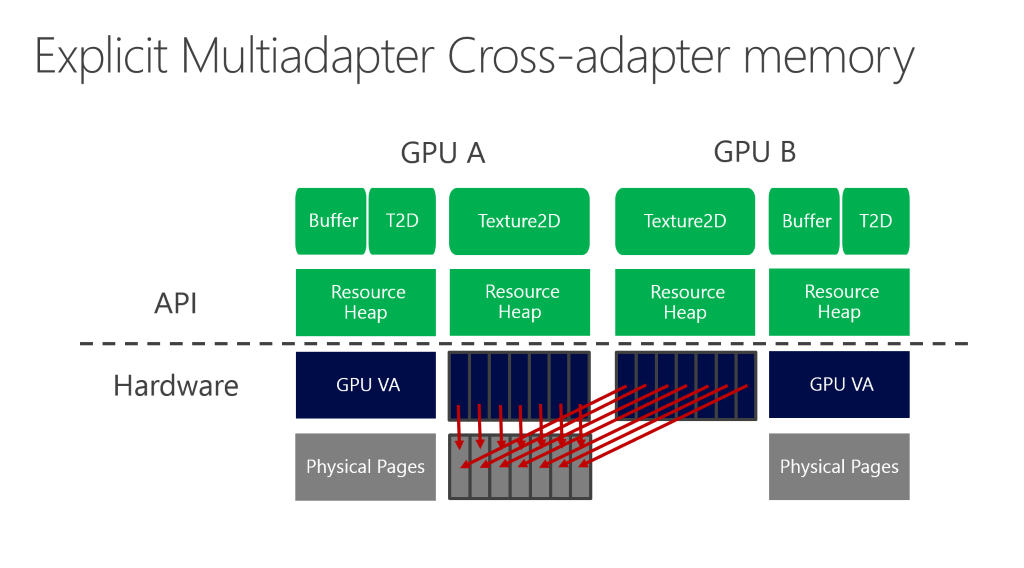
很遗憾的是,由于目前的D3D11和GLES都是在没有UMA的时代设计的,UMA并不能完全发挥功效。比如它们都推荐把数据放到buffer/texture后渲染,而又没法访问已经放进去的数据。D3D12和近期的GL/GLES扩展才把互相访问的能力发挥出来。甚至,在D3D12上,可以把集成显卡的一块区域映射到独立显卡。也就是说,让集成显卡和独立显卡协同工作。下图来自于BUILD,UE4用这种方式达到10%左右的性能提升。
hUMA呢
传统UMA的CPU和GPU虽然可以访问同一快内存区域,但它们的cache是独立的。所以如果不通过一些额外的API提醒系统,该刷cache了,轻则互访速度很慢,重则数据出错。在XBox 360中,如果不调用XProtect把一快内存设置成CPU或GPU模式,就会出现这样的情况。
AMD前不久推出了hUMA的架构,并被用于最新的APU、XBox One、PS4等地方。hUMA可以做到cache一致性。也就是说,CPU写入的数据,GPU可以直接通过cache读到,反之亦然。这样的UMA才是个完整的UMA。不再需要额外设置。
UMA不能做什么
很多人其实对UMA抱有不切实际的幻想,觉得这像颗银弹,可以直击CPU/GPU编程和应用的常见问题。但其实UMA/hUMA也有很多限制,不注意这些限制的话,还不如不用UMA。
UMA不能解决读回的速度问题
经常可以看到有人抱怨从GPU读回渲染或计算结果非常慢,并把此归咎为数据传输慢。所以认为如果有UMA之后,不用传输了,所以就无此问题。实际上,读回渲染结果需要做三件事情,同步->拷贝->untile。拷贝在PCIE上是对称的,untile和tile的计算量是一样的。所以后两步和CPU拷贝到GPU所需要的开销相同。如果两方向速度严重不对等,就必然是同步造成的。GPU的一个基本常识就是,它的渲染是并行和异步于CPU的。CPU提交的draw call最多有可能在3帧以后才被GPU执行。由此保证了GPU能塞尽量多的数据,提升吞吐量。所以,一旦需要同步,GPU就会被强制启动,把当前流水线中的所有东西执行完。相当于CPU和GPU之间是串行工作的。性能由此大减。
再有UMA的情况下,如果GPU可以渲染untile的数据,那么后两步可能被省略,否则仍然需要做这三件事情,一个都少不了。但前面已经说了,后两部的开销非常少,几乎所有时间都花在同步上了。而同步无论如何都会存在。所以UMA并不会在读回速度上有任何改善。
另一方面,如果只有UMA没有hUMA,GPU在渲染完之后,CPU如果要立刻读取,就完全无法从cache读,而每一次都得从内存直接读。性能降低上千倍也不奇怪了。
UMA不能显著提升性能
正如前面所说,如果硬件支持hUMA,并且支持渲染untile数据,才有可能完全不拷贝。即便如此,拷贝数据所占的时间非常少,所以把它省去也不会提升多少。
总结
UMA需要硬件、驱动、软件全都支持,才能发挥出功效。其主要作用是对内存的节省,并带来少量性能的提升。有些应用,比如transient buffer,可以利用UMA减少一些额外拷贝。



Comments