去年4月,Forward+刚出来的时候,我写过一篇介绍的文章。很遗憾的是,原来的paper只比较了Forward+和传统Deferred,甚至是个没怎么好好优化的Deferred。对于Tiled Deferred(TD)的比较,一直都没见到详细的。今年GDC上,终于看到了一个对Forward+和Tiled Deferred的全面性能对比,包括不同光源数,不同render target(RT)个数和是否MSAA。
别的不说,直接看结论阶段。
算法分析
首先是对Forward+和Tiled Deferred的算法分析,列出可能影响性能的地方。

RT数量对比
G-Buffer包含了多少个render target,也就是用多少带宽,对性能应系那个很大。第一轮是关闭MSAA,三角形数量较多(1.25M个),Forward+和RT数量不同的Tiled Deferred实现做性能对比。
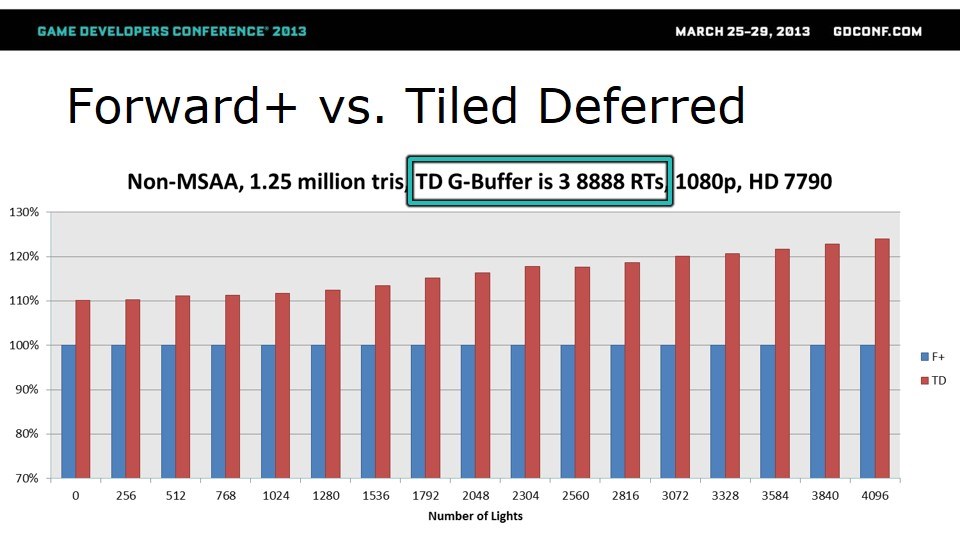
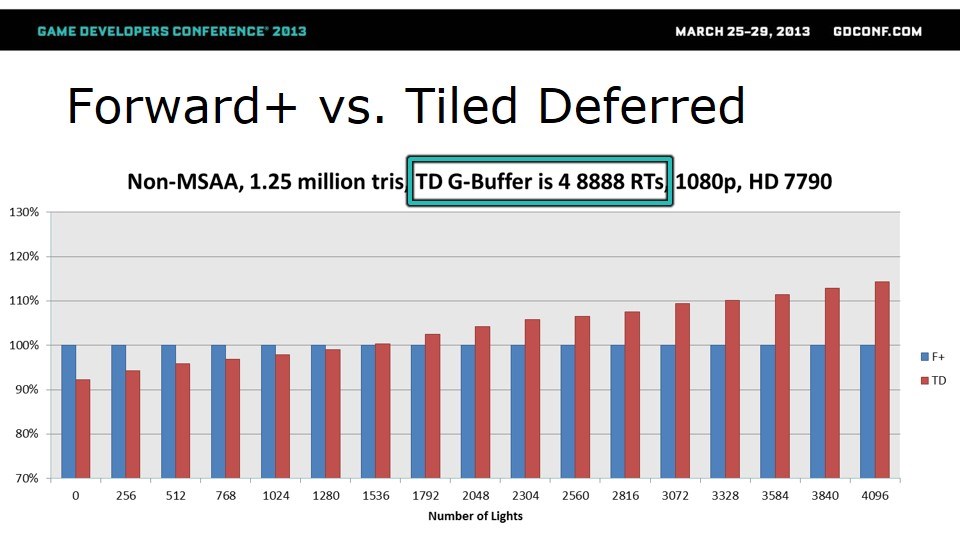
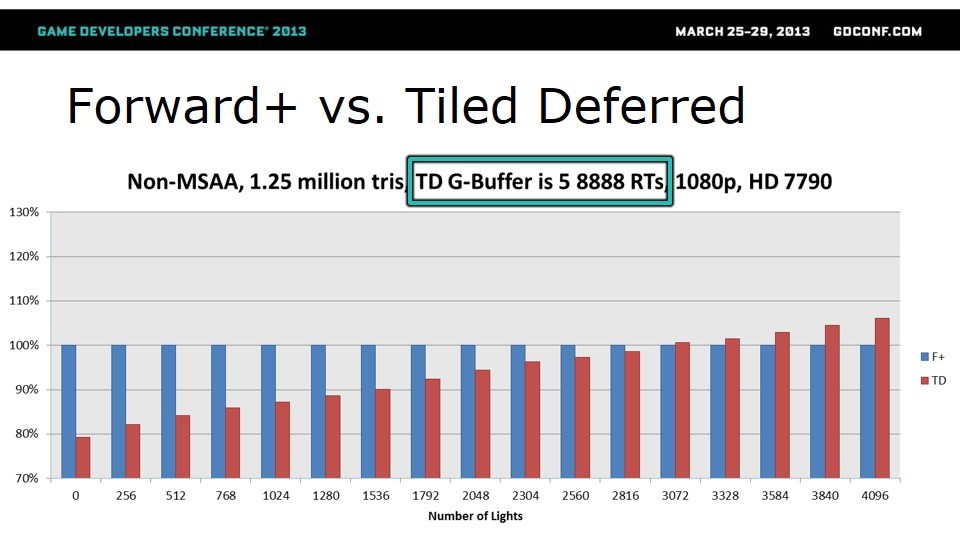 从这里可以看出,在没有MSAA、三角形较多、RT是3个的时候,无论如何TD要快。RT是4个的时候,光源少于1536的话,TD快。RT是5个的时候,除非光源非常多,否则Forward+都能快。但实际游戏使用的G-Buffer基本都只有3个RT甚至2个RT,所以这一轮显然TD胜出。
从这里可以看出,在没有MSAA、三角形较多、RT是3个的时候,无论如何TD要快。RT是4个的时候,光源少于1536的话,TD快。RT是5个的时候,除非光源非常多,否则Forward+都能快。但实际游戏使用的G-Buffer基本都只有3个RT甚至2个RT,所以这一轮显然TD胜出。
三角形数量对比
Forward+因为需要多次光栅化,在三角形数量多的时候可能会慢很多。前面一轮对比用的是1.25M个三角形,这一轮用750k的。
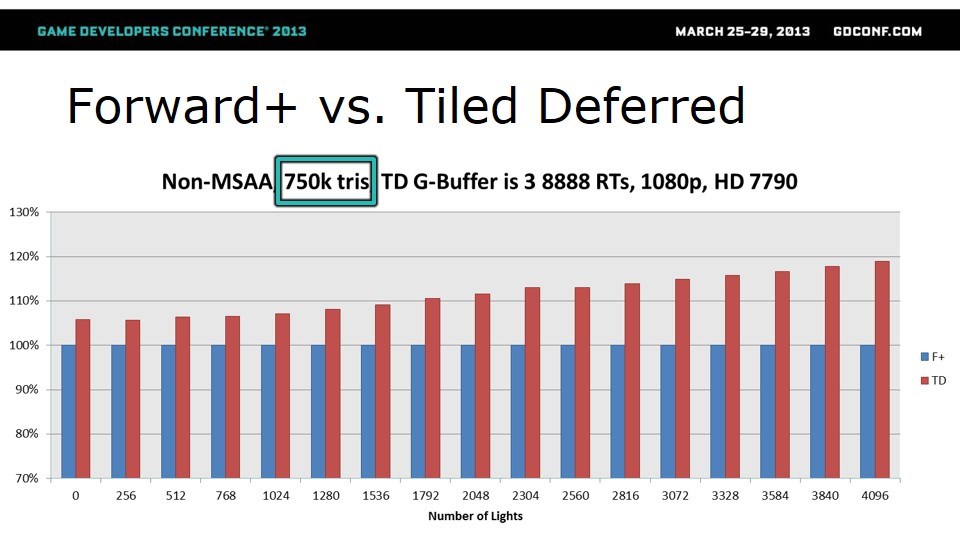
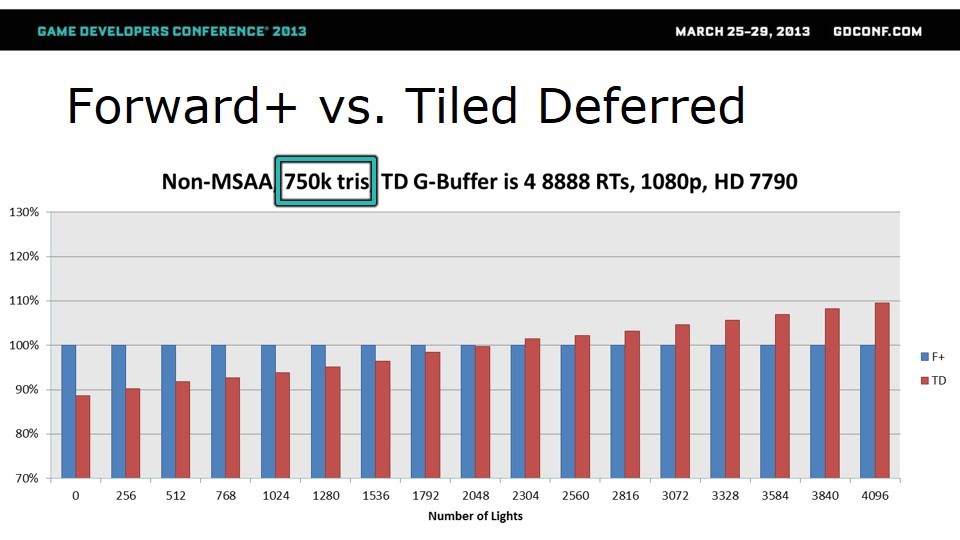
和预期一样,三角形较少的时候,TD的优势没那么明显。但如果用3个RT,TD还是能保证无论如何都快。4个RT的时候,分水岭挪到了2048个光源。这一轮,仍然是TD胜出。
MSAA开关对比
MSAA是Forward+的强项。因为不需要反复读写MSAA的数据,Forward+的带宽需求明显小于TD。
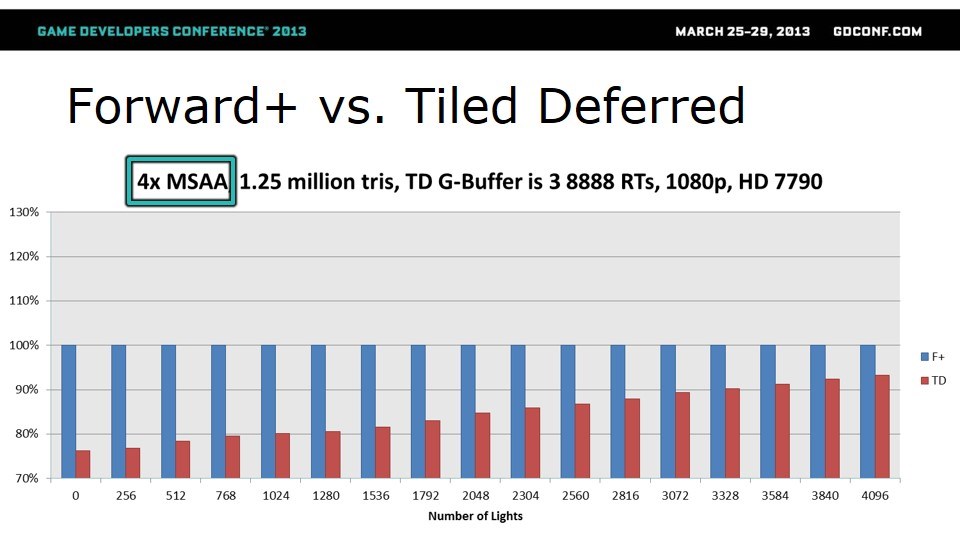 测试结果表明,只要开了4x MSAA,即便三角形有1.25M,即便只有3个RT,Forward+仍然大幅度领先。但是,正如我在Anti-alias的前世今生系列文章中指出的那样,MSAA实际上是个巨大的浪费,很多不需要重复计算的fragment都被算了多遍。反观各种post-process AA,在几乎不损失性能的情况下也能达到非常接近4x MSAA的效果。这样的话,为什么要4x MSAA呢?所以这一轮,Forward+虽然获胜,但没有任何实际意义。
测试结果表明,只要开了4x MSAA,即便三角形有1.25M,即便只有3个RT,Forward+仍然大幅度领先。但是,正如我在Anti-alias的前世今生系列文章中指出的那样,MSAA实际上是个巨大的浪费,很多不需要重复计算的fragment都被算了多遍。反观各种post-process AA,在几乎不损失性能的情况下也能达到非常接近4x MSAA的效果。这样的话,为什么要4x MSAA呢?所以这一轮,Forward+虽然获胜,但没有任何实际意义。
最终结论
除非你一门心思想用硬件MSAA,否则好好优化Tiled Deferred比切换到Forward+要现实得多。



Comments